
.jpg%3Ftable%3Dblock%26id%3D3c0955d2-04ce-4d36-bd11-62c60acade31%26cache%3Dv2&w=3840&q=75)

Experience is Directly Proportional to Broken Equipment.
Blog Posts


Eero Networking
Monitoring my Eero Network
Oct 4, 2024
Software Development
Projects
security


My Environment - 2024
My terminal environment in 2024
Sep 12, 2024
Software Development
Tech
Tips & Tricks


AWS Chime Video Reconstruction
Python Script to reconstruct Chime Video
Apr 8, 2024
OSS
Software Development
Tips & Tricks


TheAITraveler & MultiverseDreaming
More improvements, and a new channel!
Aug 29, 2023
Software Development
Creator Economy
AI

TheAITraveler Improved
New and improved!
Aug 9, 2023
Research
Software Development
Projects
Creator Economy


The AI Traveler
AI driven short-form content, autonomously
Jul 26, 2023
Computer Science
Software Development
Projects
Thought Experiments


Playing with Google Bard
Fun Times with AI
Mar 26, 2023
Computer Science
Thought Experiments
Research


My 2021 Tesla Model 3 in 2022
One Year of owning a Tesla Model 3
Jan 4, 2023
Lifestyle
Tech


Startups & Team Friction
Why do so many successful startups flame-out?
Dec 27, 2022
Tech
Lifestyle
Software Development


Location Tracking.. In Cars?
Planes, Trains, and Automobiles…
Dec 15, 2022
Lifestyle
Tech
security


Windows Text Expanders & Launchers
espanso, Fluent search, and why isn’t this built-in?
Dec 10, 2022
Software Development
Tech
Tips & Tricks

Quiet Quitting and Mattering
What is “Mattering” and why should I Care?
Nov 30, 2022
Career
Lifestyle
Thought Experiments


How bad is Technical Debt, really?
Two papers discuss the impacts of Technical Debt
Nov 28, 2022
Career
Software Development
Computer Science

1Password & Github SSH Keys on Windows
How to use multiple Github accounts on Windows with 1Password
Nov 25, 2022
Tips & Tricks
Software Development


The Meltdown of Twitter - a Timeline
The saga so far, told by insiders..
Nov 24, 2022
Career
Lifestyle
Tech


Emotional Intelligence & Leadership
How important is Emotional Intelligence in Team Leadership?
Nov 23, 2022
Career
Lifestyle


Immortality Projects and Not Giving a F*ck
How “The Subtle Art of Not Giving a F*ck” changed my life
Nov 21, 2022
Thought Experiments
Lifestyle
Career


Migrating from Evernote to Notion
How to move your data from Evernote to Notion for free!
Nov 19, 2022
Software Development
Lifestyle


Yeraze’s Domain 4.0
New and Improved, powered by NextJS & Notion
Nov 19, 2022
Web Dev
React.js

DALL-E
AI Art, just don’t expect it to look like people
Aug 20, 2022
AI

MidJourney - Art by AI
AI Art, trained by Instagram
Aug 8, 2022
AI


The MetaVerse: Applications
How do you build applications in the Metaverse?
May 14, 2022
metaverse


The MetaVerse : Maps and Location
How do you manage maps and location in the Metaverse?
May 9, 2022
metaverse


The MetaVerse
What is the Metaverse? And why should anyone care?
Apr 13, 2022
metaverse


Lacrosse Gear Drying Rack
One family’s solution to stinky teenagers
Apr 13, 2022
makers

DIY Slide Out Pantry
Converting a 2ft deep cabinet into dual slide-outs
Apr 13, 2022
makers

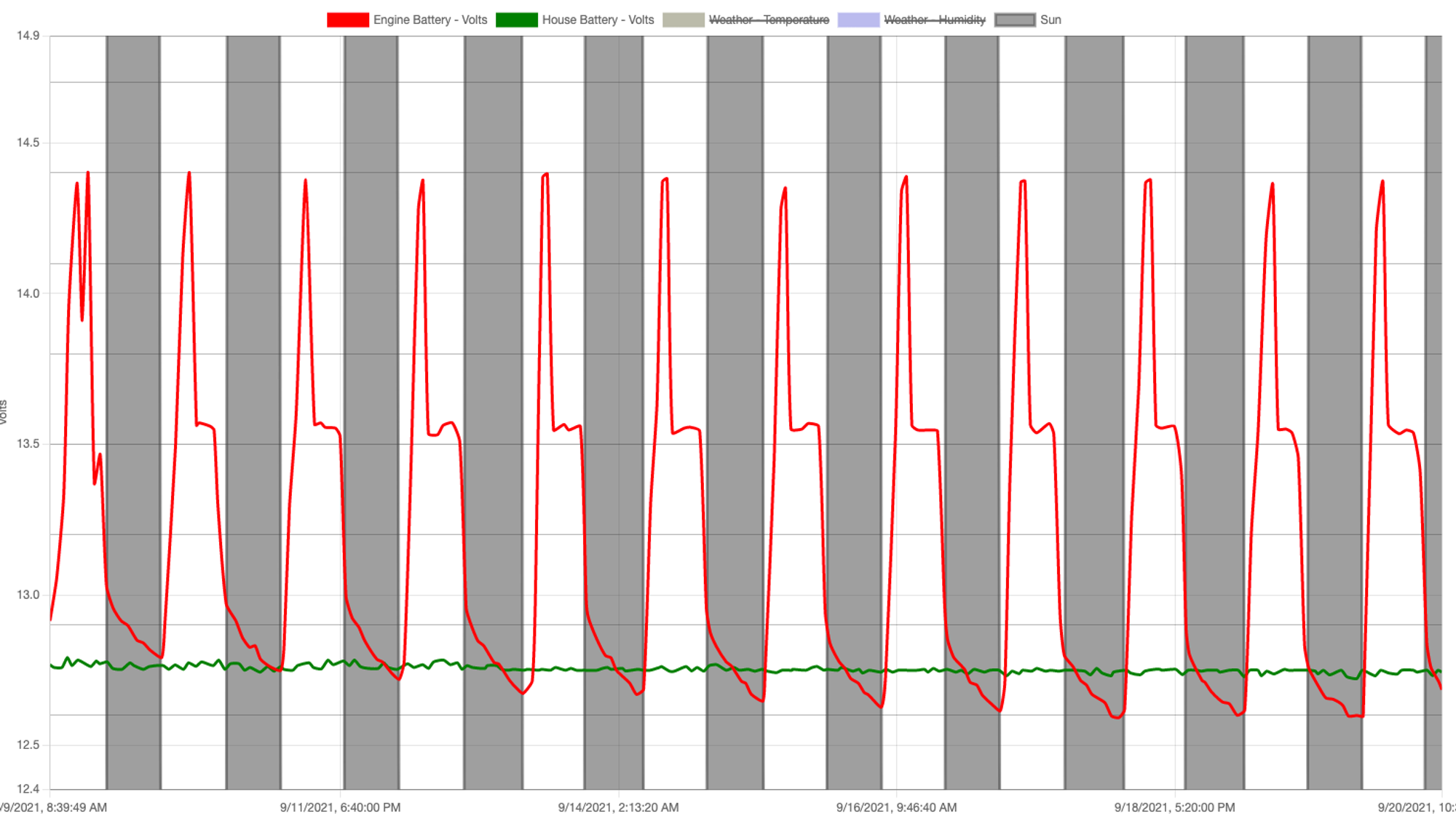
Solar Charging details
Discoveries in Solar charging
Oct 6, 2021
Data Visualization
Software Development
Computer Science
OSS


So I bought an RV....
Trying real hard not to be Cousin Eddie
Oct 3, 2021
Projects
Software Development
OSS
Data Visualization


More Audiobook Recommendations
Audible recommendations from 2019
Nov 19, 2019
audiobook

The Antidote: Happiness for People Who Can't Stand Positive Thinking
Justification for being a grump
Feb 27, 2019
audiobook


Audiobooks
Audible recommendations in business and leadership
Feb 19, 2019
audiobook

Netgear R7000N Nighthawk: A later opinion..
Firmware flakiness take it from Fantastic to Functional. Mostly..
Jul 22, 2018
hardware

Netgear R7000N Nighthawk
Massive power in a tiny box
Jul 1, 2018
hardware


Remarkable Tablet
The closest thing to real paper I’ve ever seen in a tablet
Jun 24, 2018
hardware

New Hobby: Woodworking
Earning my Man Card with a table saw
Jun 13, 2018
makers
Giving up on PGP (Kinda)
Lots of potential, but a usability nightmare
Dec 11, 2016
security


Google Hangouts link in Calendar
Aug 23, 2016
Software Development

Google Sheets - Color by Number of Entries
Aug 2, 2016
Software Development
Tips & Tricks


Fallout Shelter is a Pretty Game
Apr 12, 2016
Video Games


Traveling to Tel-Aviv, Israel
Jan 23, 2016
Lifestyle
Travel

Gogo and SSL Certificates Part 2
Jan 10, 2015
Computer Science
security
Gogo and SSL Certificates
Jan 5, 2015
Computer Science
security

Plotting Data in GDB
Oct 9, 2014
Data Visualization
Computer Science
Tips & Tricks


The Cloud Fumbles
Jun 18, 2014
Computer Science
Software Development

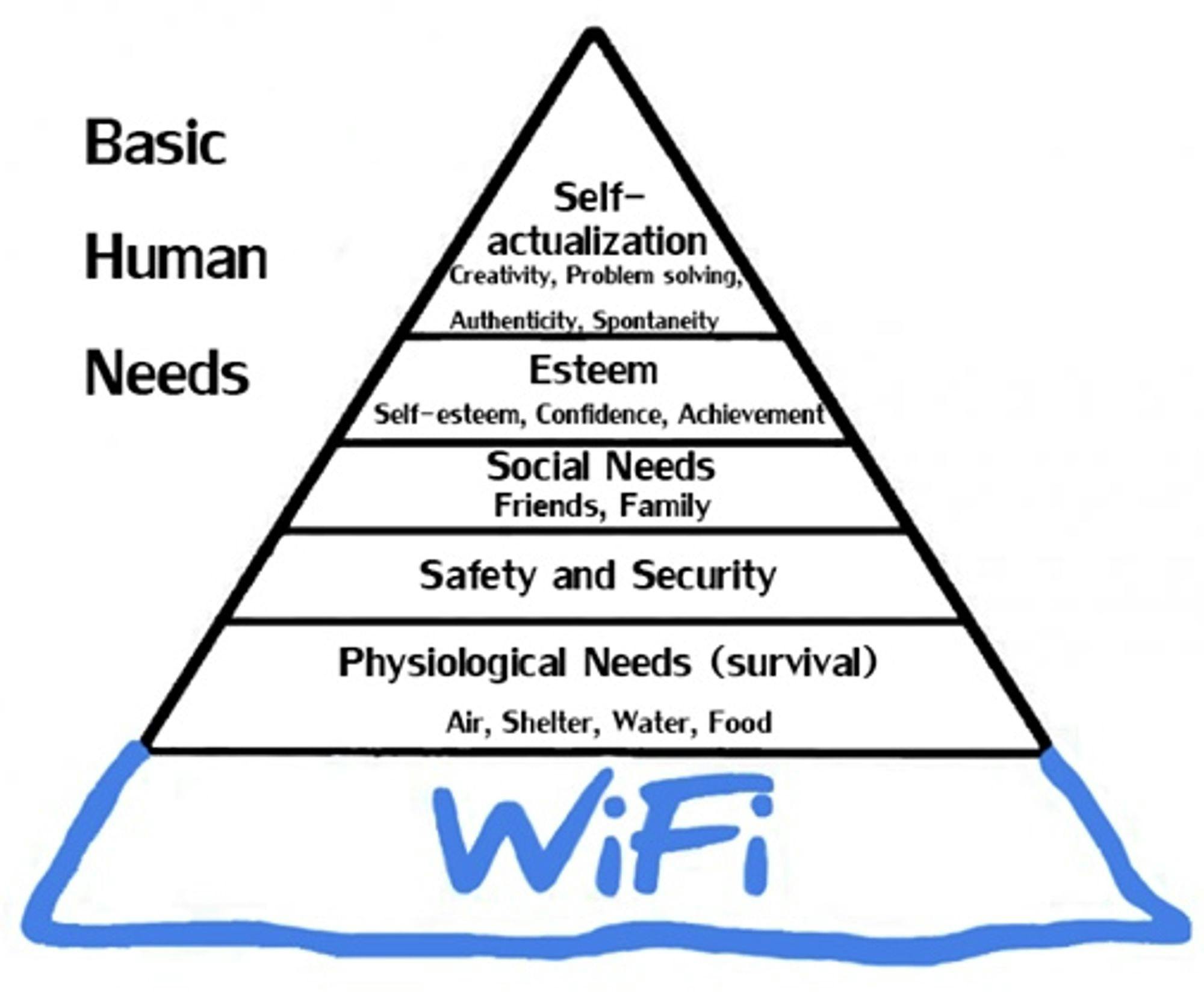
Maslow's Hierarchy of Needs - for the 21st Century
Apr 18, 2014
Thought Experiments
Lifestyle

Neat Bash Tricks
Mar 21, 2014
Tips & Tricks
Computer Science
Software Development
Sublime Text, Xeno, and Build Systems
Jan 12, 2014
Tips & Tricks
Computer Science
Software Development
A Better Way to fix OSX Calendar & Google Hangouts
Dec 23, 2013
Tips & Tricks
Computer Science
Software Development
Fishshell: CMake & finding source directories
Dec 21, 2013
Tips & Tricks
Software Development
Computer Science
FishShell: Create & Expand compressed archives
Dec 21, 2013
Computer Science
Software Development
Tips & Tricks
Xeno opening Sublime Projects
Dec 18, 2013
Computer Science
Software Development
Tips & Tricks
Tar/Untar on OSX/Linux with pretty progress bars
Dec 18, 2013
Tips & Tricks
Software Development
Computer Science
Handy Git Configuration
Dec 4, 2013
Software Development
Tips & Tricks
Computer Science
More Xeno & Fish!
Nov 27, 2013
Computer Science
Software Development
Tips & Tricks
FishShell and Xeno.io
Nov 25, 2013
Computer Science
Software Development
Tips & Tricks
Connecting Google Hangouts to OSX Calendar
Nov 18, 2013
Software Development
Tips & Tricks
Trying out ThinkUp
Nov 3, 2013
Software Development
Computer Science


TS Karen, or the Flood that Wasn't
Oct 7, 2013
Lifestyle

Mississippi State Fair 2013
Oct 6, 2013
Lifestyle


Government Shutdown 2013
Oct 2, 2013
Career
Lifestyle


MyOpenID Closing
Sep 28, 2013
Software Development


Welcome!
Sep 28, 2013
Web Dev